Using The Generic Module
- Author
Liron Levin
- Affiliation
Bioinformatics Core Facility
- Organization
llse Katz Institute for Nanoscale Science and Technology, Ben-Gurion University of the Negev, Beer-Sheva, Israel
Note
In order to use this Tutorial first:
Install NeatSeq-Flow using conda
Make sure that conda is in your PATH.
Table of Contents:
Short Description
The Generic module enables the user to design new modules (To assimilate new programs/scripts) as part of his NeatSeq-Flow Work-Flows.
- Main Features:
Easy and fast way to create new modules.
Can be used for both publicly available as well as in house programs/scripts.
Can handle most Linux programs.
No programing knowledge required.
In this Tutorial we will learn how to use the Generic module by implementing the well known BLAST tool as a test case.
Why BLAST? Although NeatSeq-Flow already has pre-build BLAST modules, it will be easier and more effective to demonstrate the functionality of the Generic module on a well known tool such as BLAST.
In this Tutorial we will follow a standard procedure of antibiotic resistance search in genomes of bacterial isolates using BLAST:
Download three bacterial genomes and the CARD Antibiotic Resistance Protein Database.
Design a Sample file for the Dataset
Design a BLAST-Database creation module.
Design a BLAST-Search module.
Attention
It is ESSENTIAL to understand the NeatSeq-Flow’s Data-Structure concept in order to use the Generic module. Read the next section CAREFULLY.
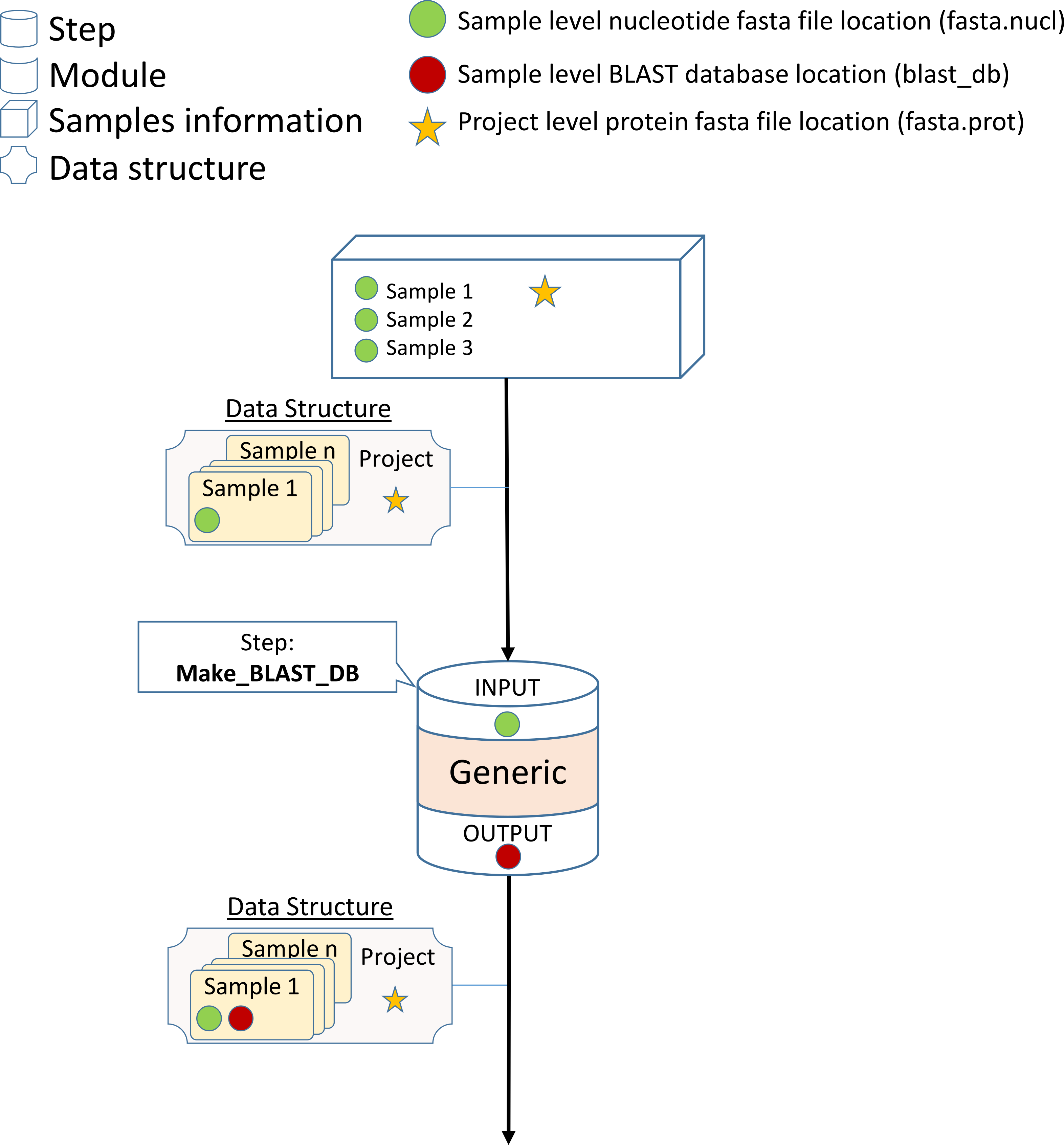
NeatSeq-Flow’s Data-Structure Concept
NeatSeq-Flow uses a Data-Structure to pass information between the Work-Flow steps. Typically, the information is the location of files, and they are stored on a file type bases:
One can imagine the Data-Structure as a chest of drawers, each drawer is labeled as different file type and its content is the location of this file type.
Each sample in the analysis has its own chest of drawers.
There is an additional chest of drawers for the entire project.
Information that is sample’s specific is stored in the sample chest of drawers.
Information that is shared between all samples is stored in the project chest of drawers.
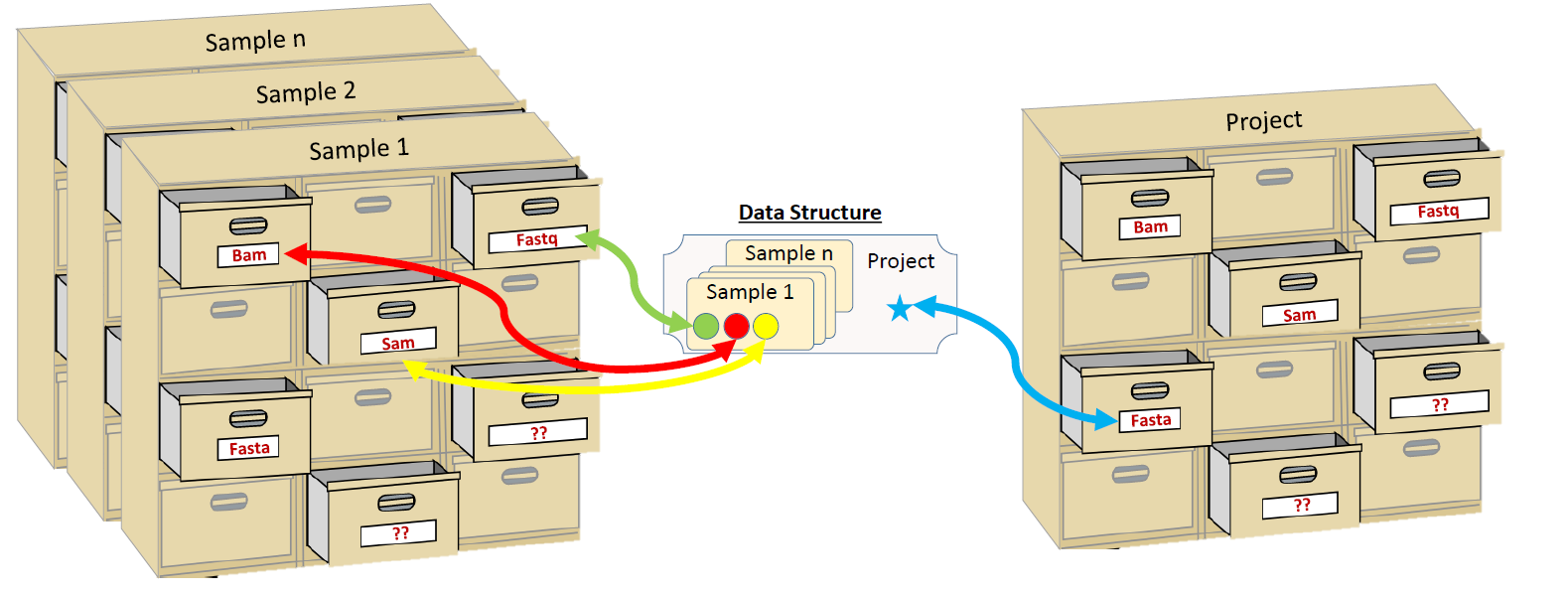
There are the typical file types such as FASTQ,FASTA,SAM,BAM however, the user can create and define new file types.
Typically, modules will search the relevant chest of drawers (sample or project part of the Data-Structure) for their input data (files locations).
Modules will add or modify the relevant part of the Data-Structure to include their output information.
The updated Data-Structure will be passed to the next module.
Steps that get more the one Data-Structure as input will merge them in to one Data-Structure while overlapping file types will be overwritten by the first Data-Structure with the overlapping file type.
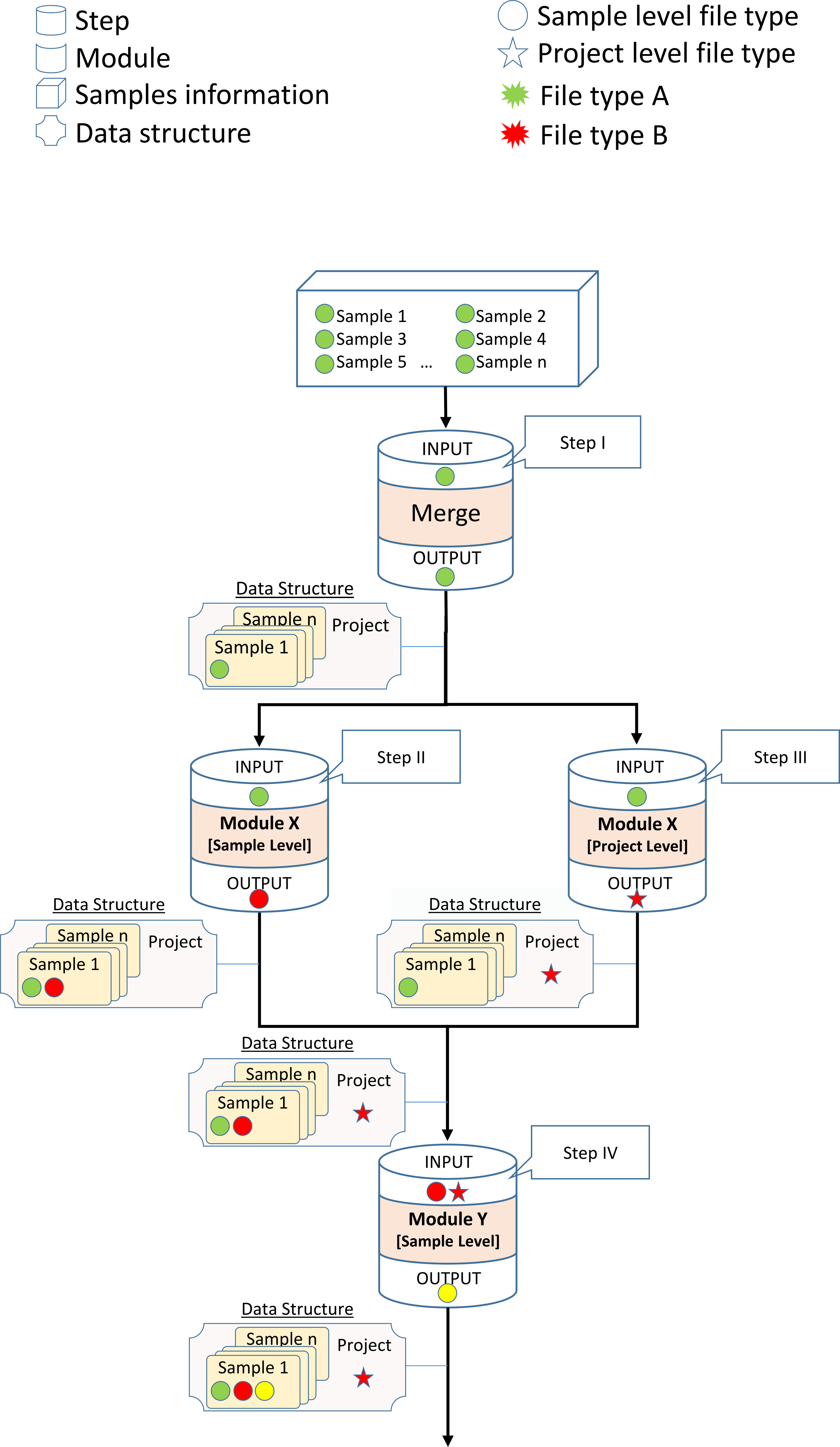
Note
While using the Generic module the user must specify the input and output file types.
Download the Tutorial Dataset
Create a Tutorial directory
In the command line type:
mkdir Generic_Module_Tutorial cd Generic_Module_Tutorial
Download three bacterial genomes
In the command line type:
curl ftp://ftp.ncbi.nlm.nih.gov/genomes/all/GCF/000/009/085/GCF_000009085.1_ASM908v1/GCF_000009085.1_ASM908v1_genomic.fna.gz > Campylobacter_jejuni.fna.gz curl ftp://ftp.ncbi.nlm.nih.gov/genomes/all/GCF/000/746/645/GCF_000746645.1_ASM74664v1/GCF_000746645.1_ASM74664v1_genomic.fna.gz > Acinetobacter_baumannii.fna.gz curl ftp://ftp.ncbi.nlm.nih.gov/genomes/all/GCF/000/005/845/GCF_000005845.2_ASM584v2/GCF_000005845.2_ASM584v2_genomic.fna.gz > Escherichia_coli.fna.gz
Download the CARD Antibiotic Resistance Protein Database
In the command line type:
curl https://card.mcmaster.ca/download/0/broadstreet-v3.0.1.tar.gz > broadstreet.tar.gz tar --wildcards *protein_fasta_protein_homolog_model* -xf broadstreet.tar.gz rm broadstreet.tar.gz
Install BLAST using CONDA
In the command line type:
conda config --add channels bioconda conda create --name Generic_Tutorial blast
Design a Sample file for the Dataset
Activate the GUI
Activate the NeatSeq_Flow conda environment:
bash source activate NeatSeq_Flow
Run NeatSeq_Flow_GUI:
NeatSeq_Flow_GUI.py --Server
Use the information in the terminal:

Copy the IP address to a web-browser - (red line)
A login window should appear
Copy the “User Name” (blue line) from the terminal to the “User Name” form in the login window
Copy the “Password” (yellow line) from the terminal to the “Password” form in the login window
Click on the “Login” button.
- In the Samples Tab:
Edit The Project Title Name by clicking on the Project Title name
Add a Project File by clicking the ‘Add project File’ button and choose the ‘protein_fasta_protein_homolog_model.fasta’ file.
Choose the ‘Protein’ file type.
Add Sample Files by clicking the ‘Add Sample File’ button and choose the three bacterial genomes files.
Choose for each of the genomes the ‘Nucleotide’ file type.
Save the Sample file by licking the ‘Save Sample File’ button and choose a new file name.
Design a BLAST-Database creation module
In this step we will create a Generic module which will create a BLAST-Database from each of the bacterial genomes.
In order to do this, we will use the ‘makeblastdb’ BLAST tool. MAKEBLASTDB the database creating tool of BLAST
Note
Whenever we want to implement a new tool, first we need to know how the command line of the program should look like.
In the case of makeblastdb for making nucleotide database:
makeblastdb \
–in nucleotide.fasta \
-out blast_db_name \
-dbtype nucl
- In the Work-Flow Tab:
Select a generic module template and click on the ‘Create New Step’ button.
- In the left panel click on the new step name and then:
In the ‘Key’ field change it to ‘Make_BLAST_DB’
Click on the ‘Edit’ button.
- In the left panel click on the ‘base’ sub-option and then:
In the ‘Value options’ choose the Merge previous step. This will indicate the order of this step
Click on the ‘Add’ button.
Click on the ‘Edit’ button.
- In the left panel click on the ‘script_path’ sub-option and then:
In the ‘Value’ field change it to ‘makeblastdb’. This will be the main command of this step.
Click on the ‘Edit’ button.
- In the left panel click on the ‘scope’ sub-option and then:
In the ‘Value options’ choose ‘sample’. This will indicate that this module will operate on each of the samples (as opposed to only once in project scope).
Click on the ‘Add’ button.
Click on the ‘Edit’ button.
- In the left panel under the ‘inputs’ sub-option click on the ‘STR’ sub-option and then:
In the ‘Key’ field change it to ‘-in’. This will indicate to use a ‘-in’ argument for this input information.
Click on the ‘Edit’ button.
- In the left panel under the ‘-in’ sub-option click on the ‘scope’ sub-option and then:
In the ‘Value options’ choose ‘sample’. This will indicate that the input information will be taken from the sample part of the Data-Structure.
Click on the ‘Add’ button.
Click on the ‘Edit’ button.
- In the left panel under the ‘-in’ sub-option click on the ‘File_Type’ sub-option and then:
In the ‘Value options’ choose ‘fasta.nucl’. This will indicate that the input information will be taken from the ‘fasta.nucl’ file type in the Data-Structure.
Click on the ‘Add’ button.
Click on the ‘Edit’ button.
- In the left panel under the ‘outputs’ sub-option click on the ‘STR’ sub-option and then:
In the ‘Key’ field change it to ‘-out’. This will indicate to use a ‘-out’ argument for this output information.
Click on the ‘Edit’ button.
- In the left panel under the ‘-out’ sub-option click on the ‘File_Type’ sub-option and then:
In the ‘Value’ field edit it to ‘blast_db’. This will indicate that the output information will be inserted to the ‘blast_db’ file type in the Data-Structure.
Click on the ‘Edit’ button.
Note
The outputs ‘scope’ is determined by the step scope.
If the output ‘File_Type’ dose not exists it will be created.
If the output ‘File_Type’ already exists it will be overwritten by the new file location.
It is impotent to remember that the information stored in the Data-Structure is only of the file locations, therefore overwriting will not change the files themselves!
- In the left panel under the ‘outputs’ sub-option click on the ‘suffix’ sub-option and then:
In the ‘Value’ field edit it to ‘_db’.
Click on the ‘Edit’ button.
Note
The outputs file locations are determent as follows:
For sample scope: The_Sample_Output_Directory/prefix+Sample_Name+suffix
For project scope: The_step_Output_Directory/prefix+Project_Title+suffix
For more options see the Generic module help
- In the left panel click on the ‘Make_BLAST_DB’ step name and then:
Click on the ‘New’ button.
Click on the ‘New’ option that was just created.
In the ‘Key’ field change it to ‘redirects’.
Click on the ‘Edit’ button.
Click on the ‘New’ button.
Click on the ‘New’ option that was just created.
In the ‘Key’ field change it to ‘-dbtype’.
In the ‘Value’ field type ‘nucl’.
Click on the ‘Edit’ button.
Note
The ‘redirects’ option is the place to indicate arguments that will be passed to the command line directly.
Use it for arguments that are the same for all samples.
Use it for arguments using information that is not from within the Data-Structure.
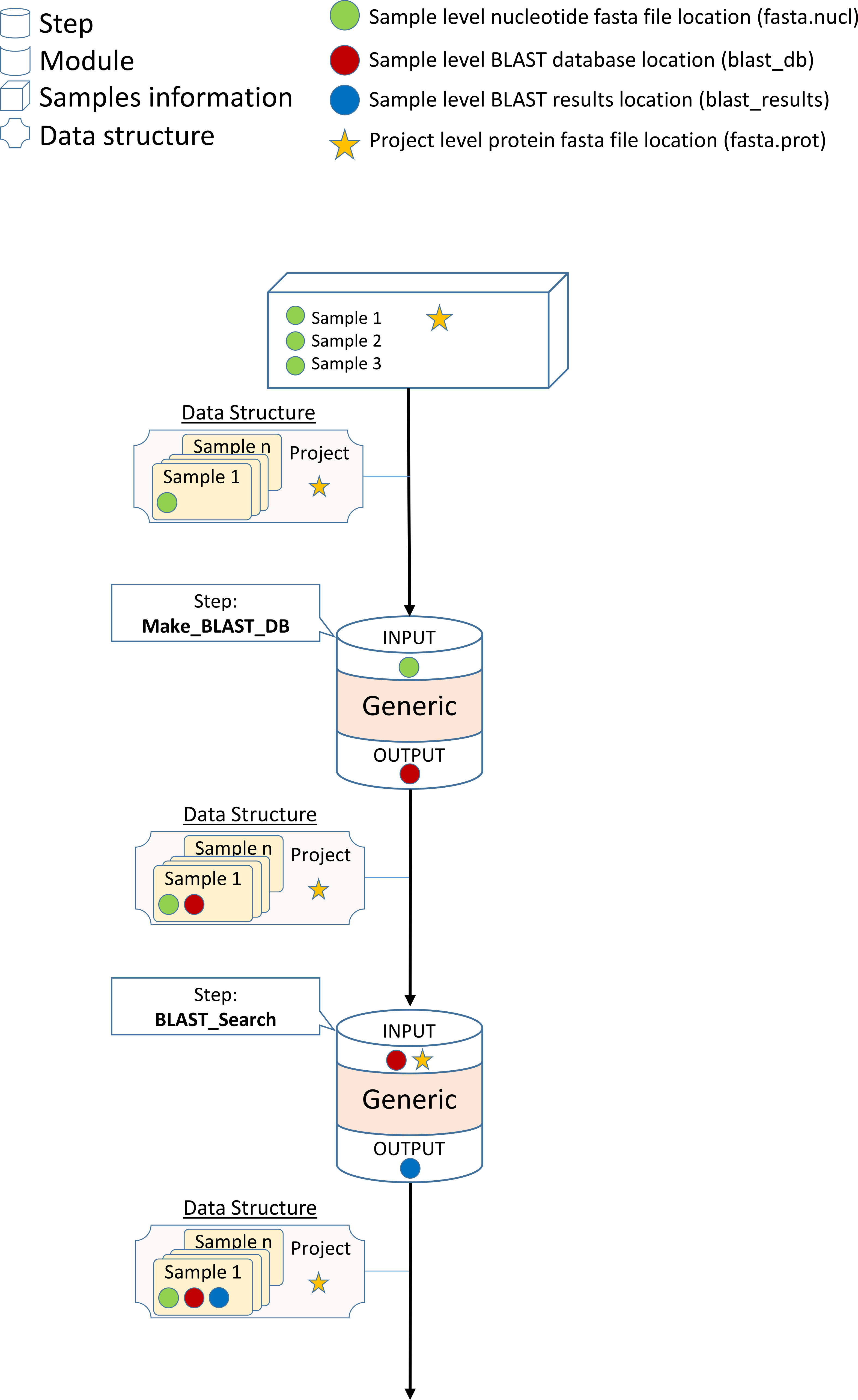
Design a BLAST-Search module
In this step we will create a Generic module which will search the BLAST database we created in the previous step using the CARD Antibiotic Resistance Protein Database . In order to do this, we will use the ‘tblastn’ BLAST tool. TBLASTN search translated nucleotide databases using a protein query.
Note
Whenever we want to implement a new tool, first we need to know how the command line of the program should look like.
In the case of tblastn :
tblastn \
–db blast_db_name \
-query protein.fasta \
-out blast_results.out \
-evalue 1e-7
- In the Work-Flow Tab:
Select a generic module template and click on the ‘Create New Step’ button.
- In the left panel click on the new step name and then:
In the ‘Key’ field change it to ‘BLAST_Search’
Click on the ‘Edit’ button.
- In the left panel click on the ‘base’ sub-option and then:
In the ‘Value options’ choose the ‘Make_BLAST_DB’ previous step. This will indicate the order of this step
Click on the ‘Add’ button.
Click on the ‘Edit’ button.
- In the left panel click on the ‘script_path’ sub-option and then:
In the ‘Value’ field change it to ‘tblastn’. This will be the main command of this step.
Click on the ‘Edit’ button.
- In the left panel click on the ‘scope’ sub-option and then:
In the ‘Value options’ choose ‘sample’. This will indicate that this module will operate on each of the samples (as opposed to only once in project scope).
Click on the ‘Add’ button.
Click on the ‘Edit’ button.
- In the left panel under the ‘inputs’ sub-option click on the ‘STR’ sub-option and then:
Click on the ‘Duplicate’ button. This will create another input sub-option block.
- In the left panel under the ‘inputs’ sub-option click on the first ‘STR’ sub-option and then:
In the ‘Key’ field change it to ‘-db’. This will indicate to use a ‘-db’ argument for this input information.
Click on the ‘Edit’ button.
- In the left panel under the ‘-db’ sub-option click on the ‘scope’ sub-option and then:
In the ‘Value options’ choose ‘sample’. This will indicate that the input information will be taken from the sample part of the Data-Structure.
Click on the ‘Add’ button.
Click on the ‘Edit’ button.
- In the left panel under the ‘-db’ sub-option click on the ‘File_Type’ sub-option and then:
In the ‘Value options’ choose ‘blast_db’. This will indicate that the input information will be taken from the ‘blast_db’ file type in the Data-Structure.
Click on the ‘Add’ button.
Click on the ‘Edit’ button.
- In the left panel under the ‘inputs’ sub-option click on the ‘STR’ sub-option and then:
In the ‘Key’ field change it to ‘-query’. This will indicate to use a ‘-query’ argument for this input information.
Click on the ‘Edit’ button.
- In the left panel under the ‘-query’ sub-option click on the ‘scope’ sub-option and then:
In the ‘Value options’ choose ‘project’. This will indicate that the input information will be taken from the project part of the Data-Structure.
Click on the ‘Add’ button.
Click on the ‘Edit’ button.
- In the left panel under the ‘-query’ sub-option click on the ‘File_Type’ sub-option and then:
In the ‘Value options’ choose ‘fasta.prot’. This will indicate that the input information will be taken from the ‘fasta.prot’ file type in the Data-Structure.
Click on the ‘Add’ button.
Click on the ‘Edit’ button.
- In the left panel under the ‘outputs’ sub-option click on the ‘STR’ sub-option and then:
In the ‘Key’ field change it to ‘-out’. This will indicate to use a ‘-out’ argument for this output information.
Click on the ‘Edit’ button.
- In the left panel under the ‘-out’ sub-option click on the ‘File_Type’ sub-option and then:
In the ‘Value’ field edit it to ‘blast_results’. This will indicate that the output information will be inserted to the ‘blast_results’ file type in the Data-Structure.
Click on the ‘Edit’ button.
Note
The outputs ‘scope’ is determined by the step scope.
If the output ‘File_Type’ dose not exists it will be created.
If the output ‘File_Type’ already exists it will be overwritten by the new file location.
It is impotent to remember that the information stored in the Data-Structure is only of the file locations, therefore overwriting will not change the files themselves!
- In the left panel under the ‘-out’ sub-option click on the ‘suffix’ sub-option and then:
In the ‘Value’ field edit it to ‘_blast_results.out’.
Click on the ‘Edit’ button.
Note
The outputs file locations are determent as follows:
For sample scope: The_Sample_Output_Directory/prefix+Sample_Name+suffix
For project scope: The_step_Output_Directory/prefix+Project_Title+suffix
For more options see the Generic module help
- In the left panel click on the ‘BLAST_Search’ step name and then:
Click on the ‘New’ button.
Click on the ‘New’ option that was just created.
In the ‘Key’ field change it to ‘redirects’.
Click on the ‘Edit’ button.
Click on the ‘New’ button.
Click on the ‘New’ option that was just created.
In the ‘Key’ field change it to ‘-evalue’.
In the ‘Value’ field type ‘1e-7’.
Click on the ‘Edit’ button.
Note
The ‘redirects’ option is the place to indicate arguments that will be passed to the command line directly.
Use it for arguments that are the same for all samples.
Use it for arguments using information that is not from within the Data-Structure.
Link the CONDA Environment and Save the Work-Flow
In this step we will link the ‘Generic_Tutorial’ CONDA environment we created before to the Work-Flow.
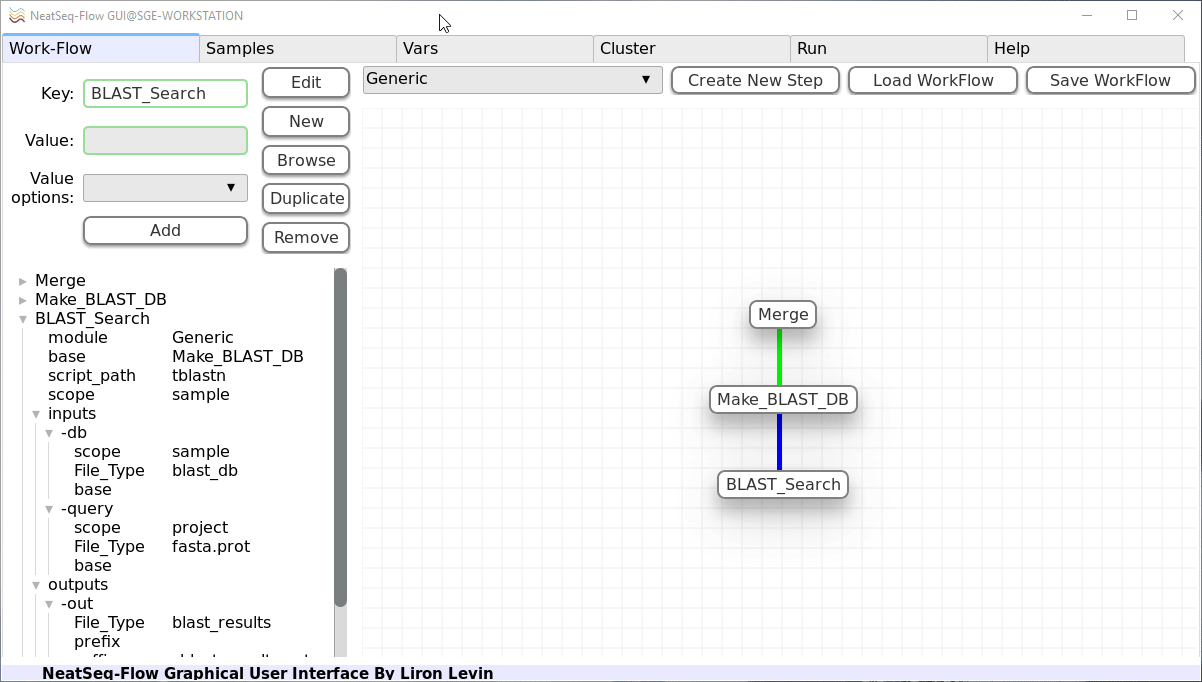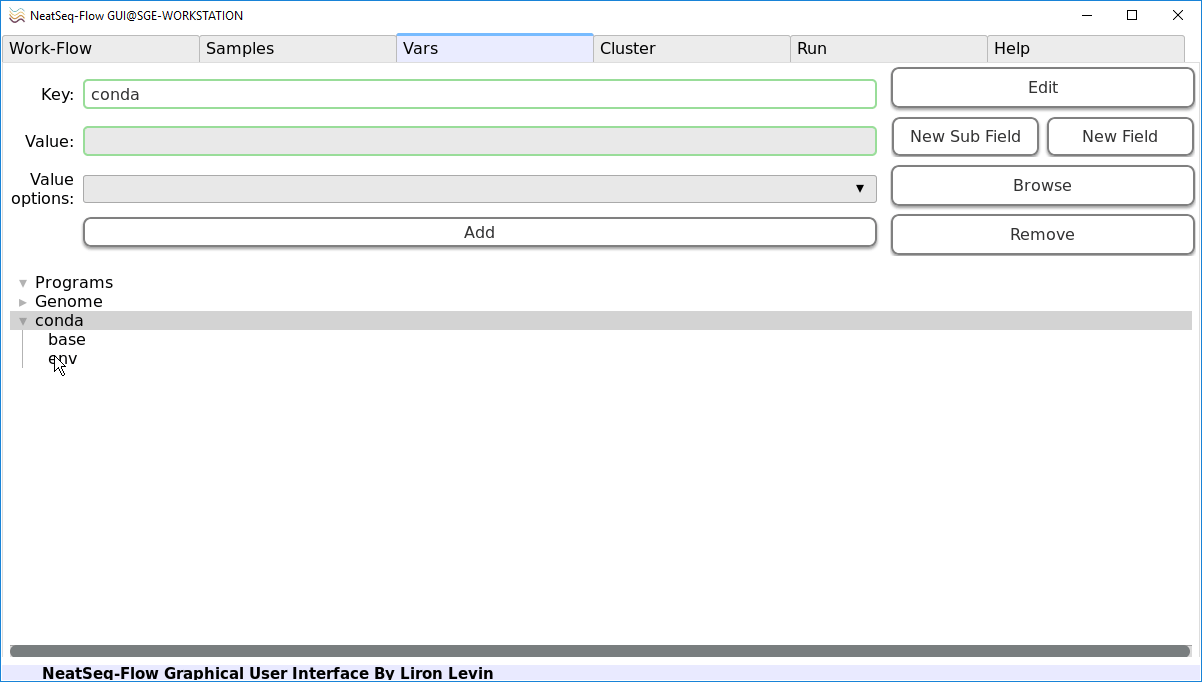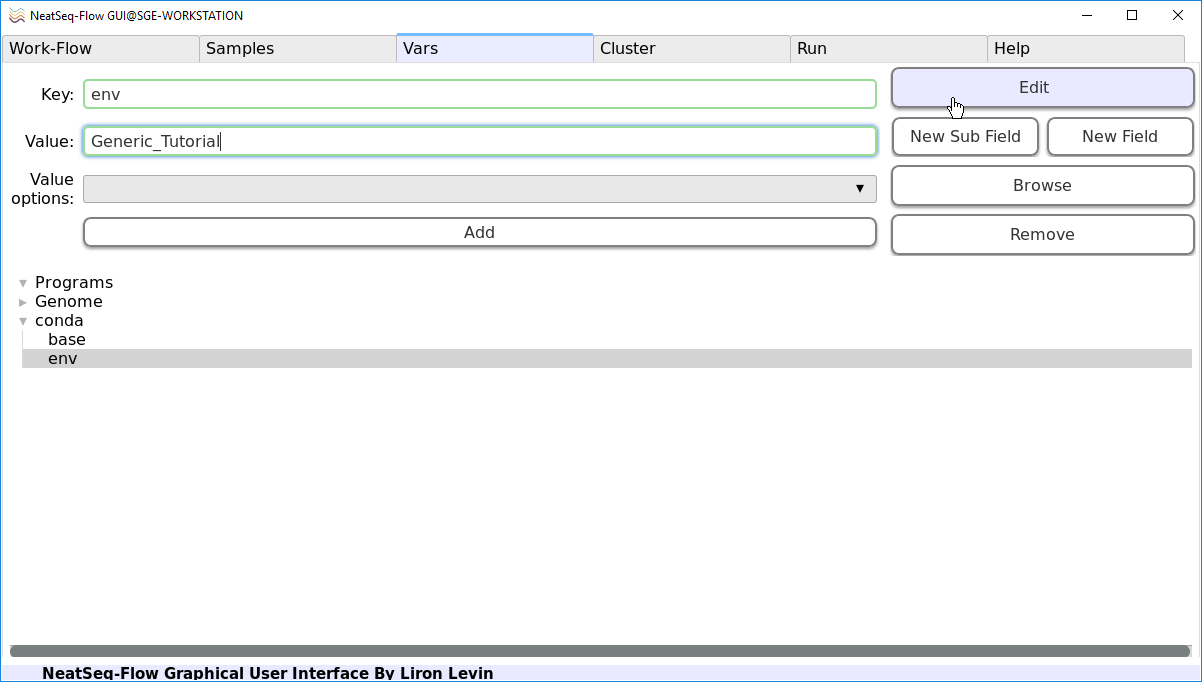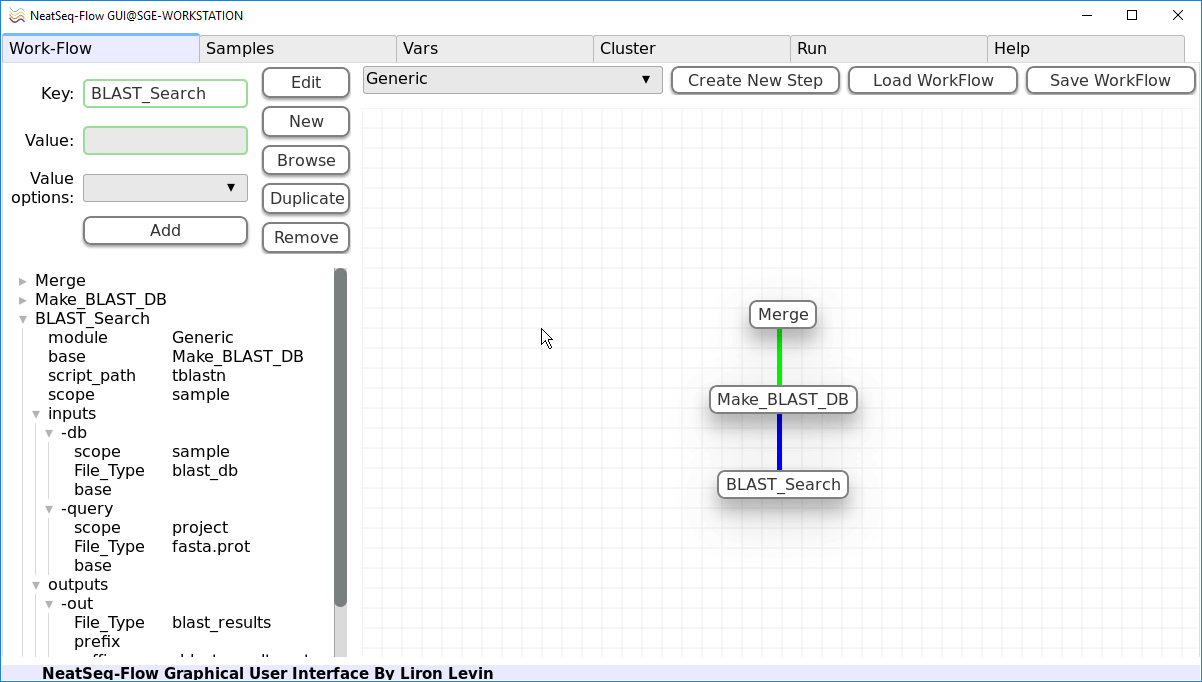
- In the Vars Tab:
Click on the triangular shape next to the ‘conda’ option in the lower panel.
Click on the ‘env’ sub-option.
In the ‘Value’ field edit it to ‘Generic_Tutorial’. This will link the ‘Generic_Tutorial’ CONDA environment to the current Work-Flow.
Click on the ‘Edit’ button.
To save the Work-Flow:
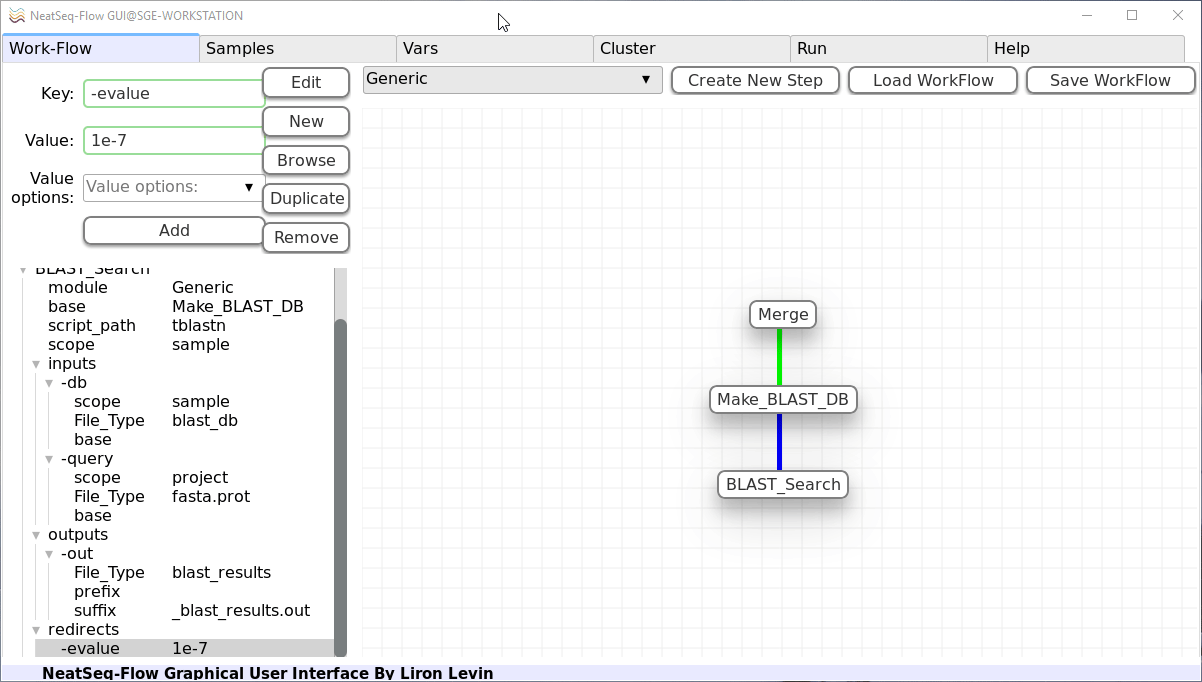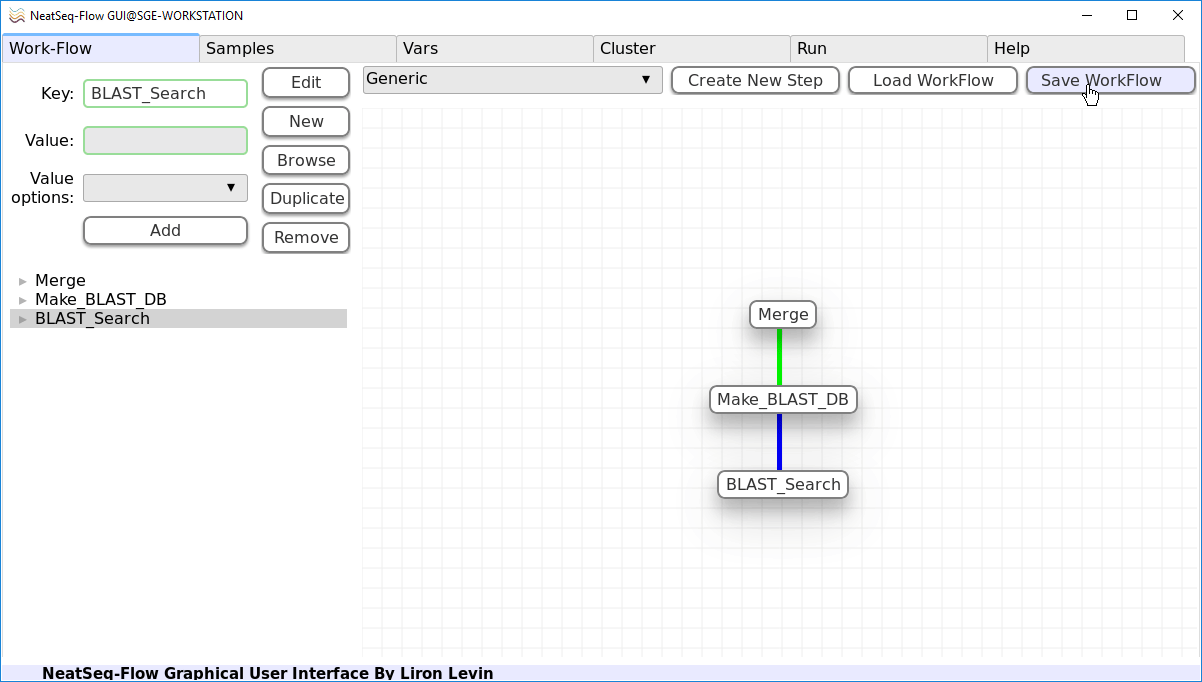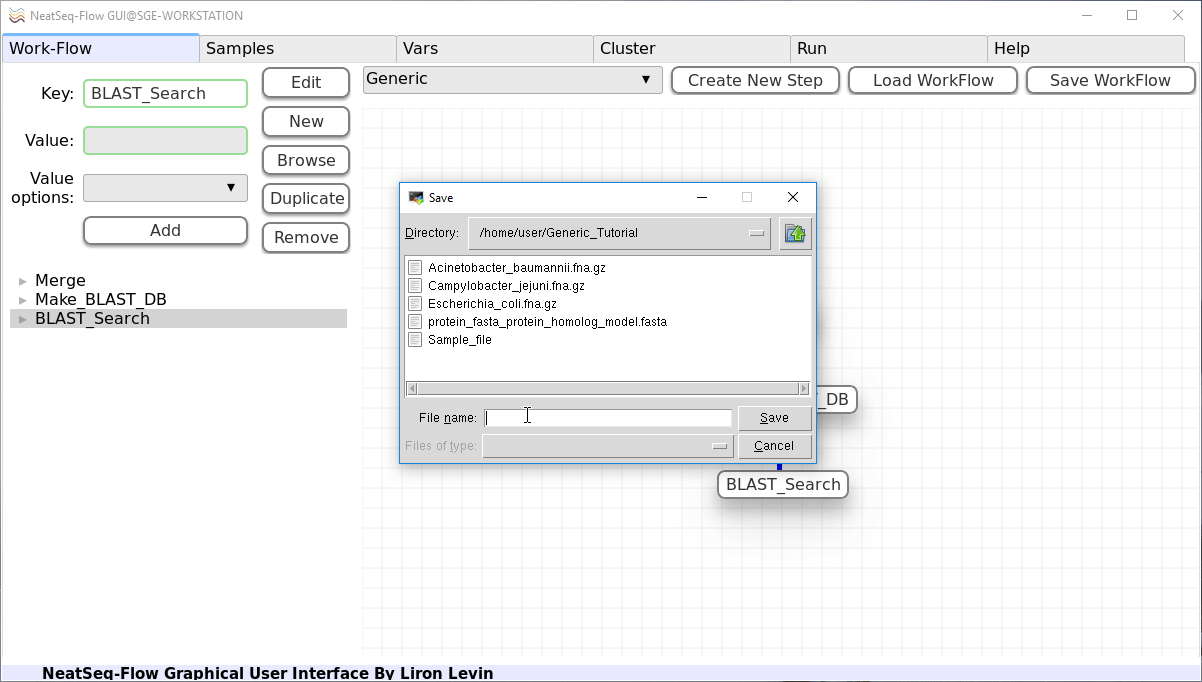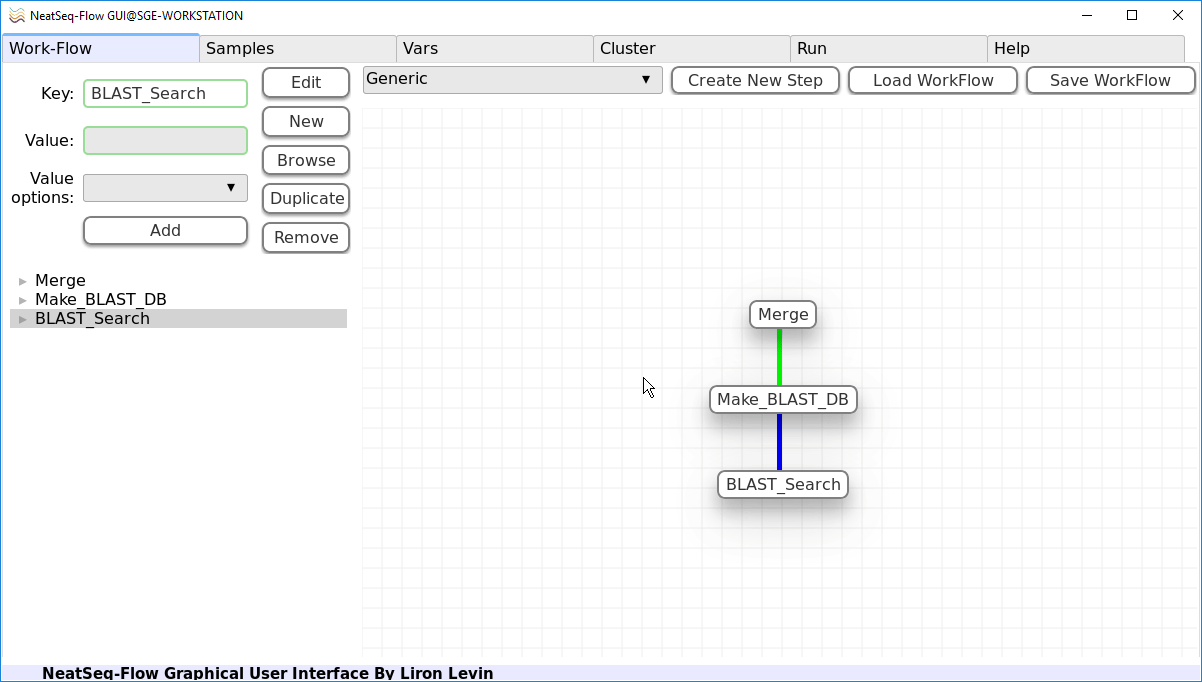
- In the Work-Flow Tab:
Click on the ‘Save WorkFlow’ button.
Type ‘Generic_Tutorial.yaml’ in the File name field to indicate the new Work-Flow parameter file.
Click on the ‘Save’ button.
Generate Scripts and Run the Work-Flow
To Generate the Work-Flow’s Scripts:
- In the Run Tab:
Click on the ‘Search’ button.
Select ‘NeatSeq_Flow’ from the Drop-down menu next to the ‘Search’ button.
Click on the ‘Browse’ button next to the ‘Parameter File’ field.
Select the ‘Generic_Tutorial.yaml’ file and click the ‘Open’ button.
Click on the ‘Browse’ button next to the ‘Sample File’ field.
Select the ‘Sample_file’ file and click the ‘Open’ button.
Click on the ‘Browse’ button next to the ‘Project Directory’ field.
Select the location were you want the analysis outputs to be saved in and click the ‘Ok’ button.
Click on the ‘Generate scripts’ button.
To Run the Work-Flow:
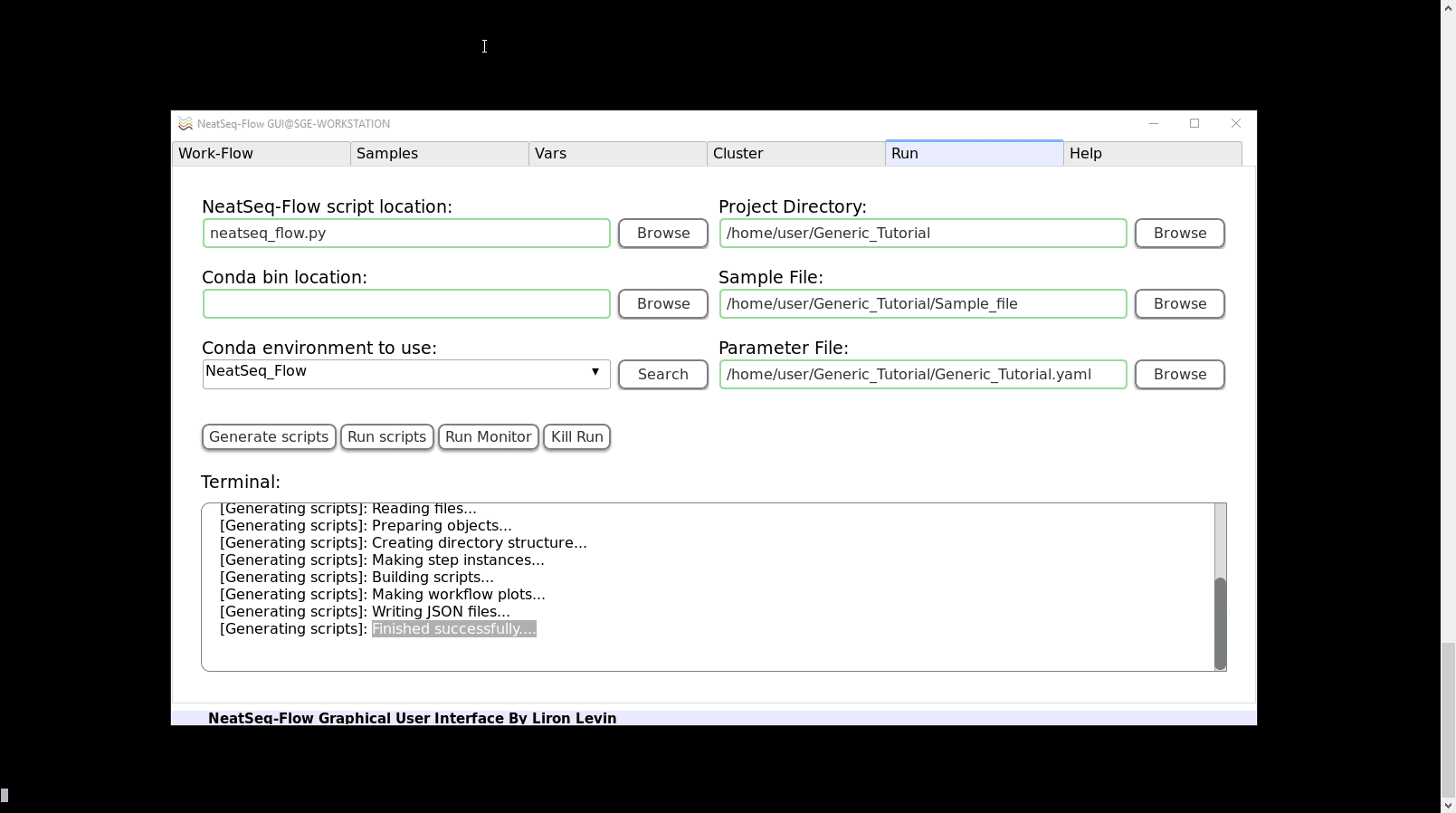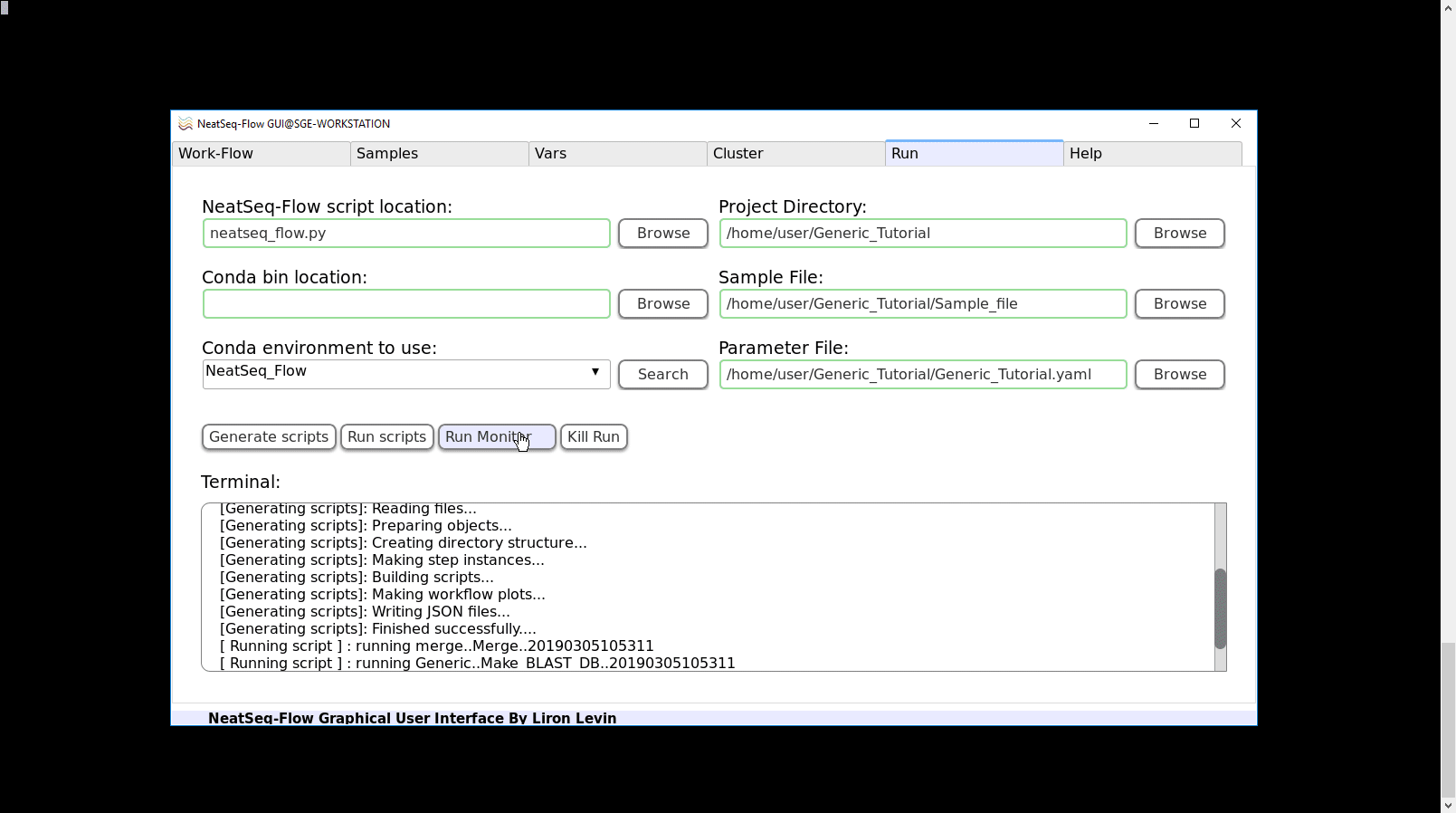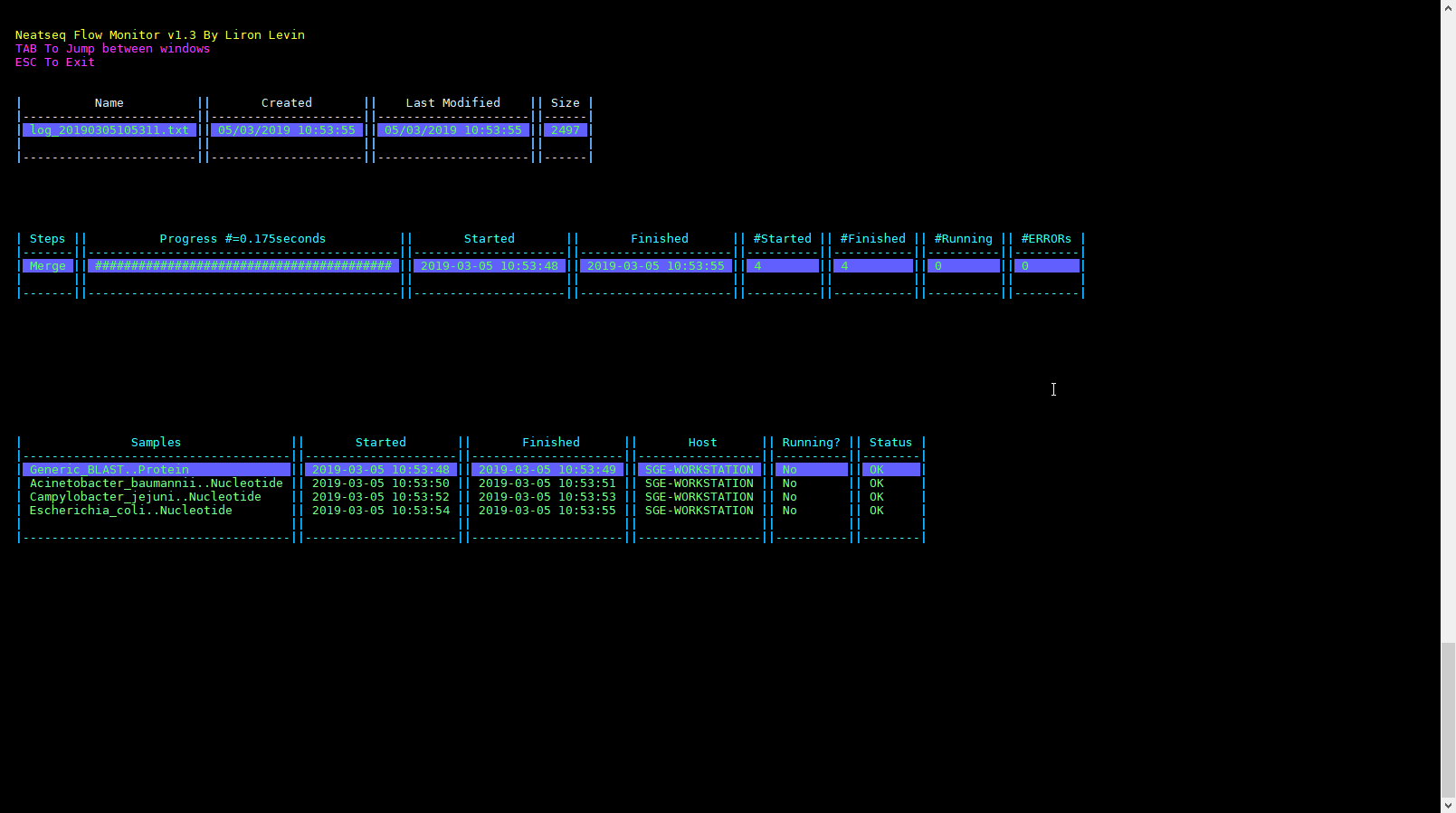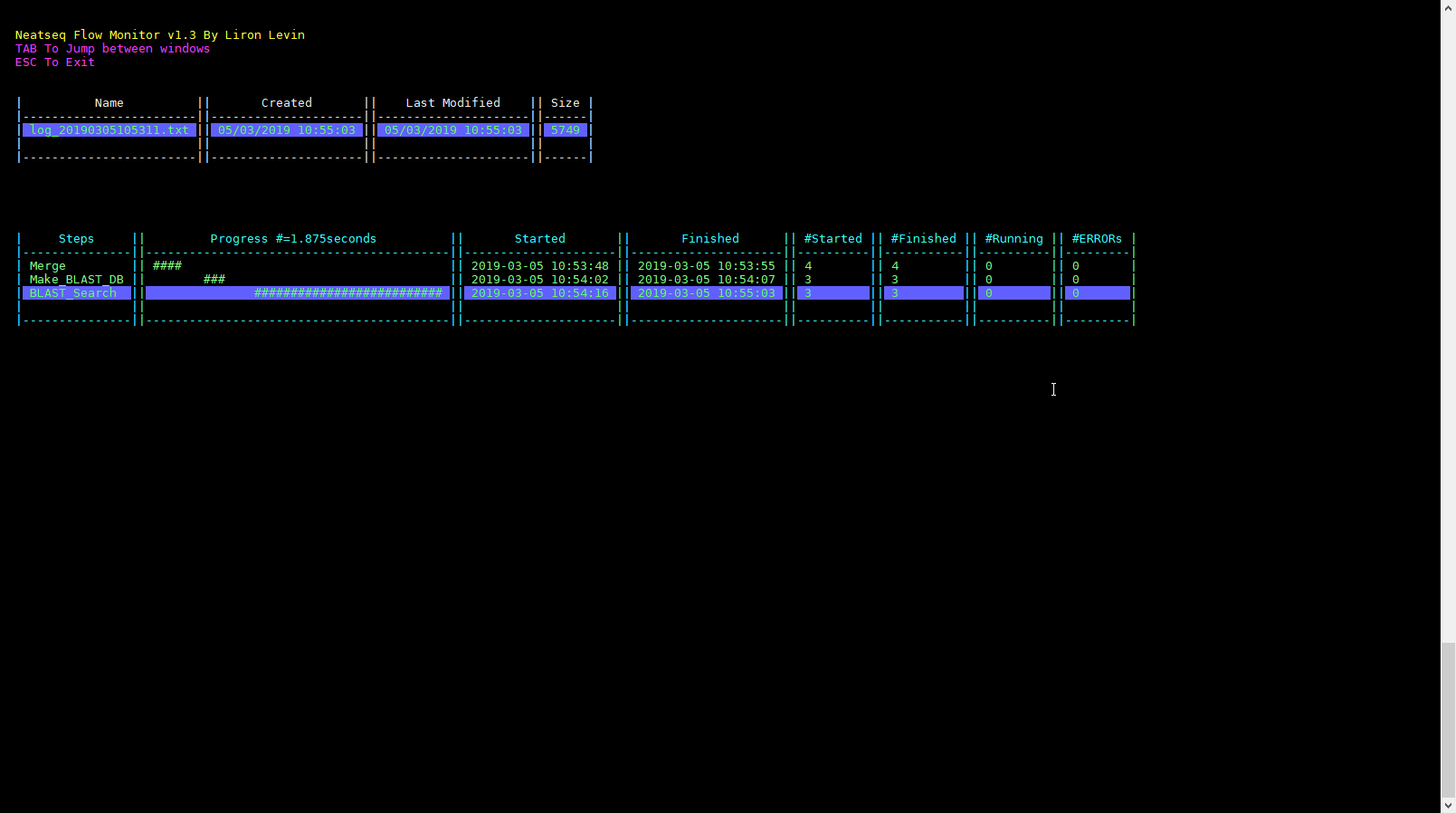
- In the Run Tab:
Click on the ‘Run scripts’ button.
Click on the ‘Run Monitor’ button.
Note
You can look at the scripts generated in the scripts directory.
You can look at the results in the data directory.
More Options for Using the Generic Module
To see the full flexibility of the Generic module go to the Generic module help in the NeatSeq-Flow module Repository